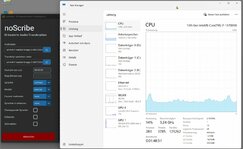
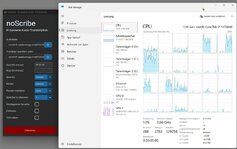
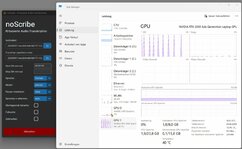
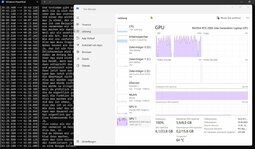
Hallo, ich beobachte häufig, dass bestimmte Rechenprozesse ziemlich lange dauern, aber (zumindest nach den Angaben z.B. im Taskmanager) nicht die volle Leistung des Computers abgerufen wird.
Hier sitze ich gerade an meinem P16 Gen 2 und lasse mit dem AI-Programm "noScribe" den Audiomitschnitt eines Vortrags in Text umwandeln. noScribe ist eine Open-Source-Software, die im Grunde eine UI für OpenAI Whisper ist.

 github.com
github.com
Eine super Sache, ich muss die Audiodatei nicht erst irgendwo in eine Cloud hochladen (und natürlich auch nichts für den Dienst bezahlen). Da wird natürlich mächtig viel gerechnet (unterstützt von der Nvidia GPU im P16), und so ein einstündiger Vortrag ist dann auch mal ca. 30 min in der Mühle - oder auch länger, wenn man noch die Sprechererkennung etwa bei einem Interview oder einer Diskussion einschaltet.
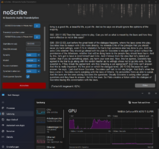
Soweit alles ok. Nur frage ich mich, warum nicht mehr Leistung abgerufen wird. Schaut euch mal den Screenshot an. Ähnliches sehe ich aber nicht nur bei diesem Programm. Auch finde ich merkwürdig, dass manchmal die CPU schon im Turbo taktet (und der Lüfter entsprechend hochläuft), obwohl die CPU nur bei z.B. 20-30% Auslastung läuft. Als Energieprofil habe ich natürlich "Beste Leistung" eingestellt.
Würde mich einfach interessieren, was da der technische Hintergrund ist. Danke schon mal.
Hier sitze ich gerade an meinem P16 Gen 2 und lasse mit dem AI-Programm "noScribe" den Audiomitschnitt eines Vortrags in Text umwandeln. noScribe ist eine Open-Source-Software, die im Grunde eine UI für OpenAI Whisper ist.
GitHub - kaixxx/noScribe: Cutting edge AI technology for automated audio transcription. A nice GUI for OpenAIs Whisper and pyannote (speaker identification)
Cutting edge AI technology for automated audio transcription. A nice GUI for OpenAIs Whisper and pyannote (speaker identification) - kaixxx/noScribe
github.com
Eine super Sache, ich muss die Audiodatei nicht erst irgendwo in eine Cloud hochladen (und natürlich auch nichts für den Dienst bezahlen). Da wird natürlich mächtig viel gerechnet (unterstützt von der Nvidia GPU im P16), und so ein einstündiger Vortrag ist dann auch mal ca. 30 min in der Mühle - oder auch länger, wenn man noch die Sprechererkennung etwa bei einem Interview oder einer Diskussion einschaltet.
Soweit alles ok. Nur frage ich mich, warum nicht mehr Leistung abgerufen wird. Schaut euch mal den Screenshot an. Ähnliches sehe ich aber nicht nur bei diesem Programm. Auch finde ich merkwürdig, dass manchmal die CPU schon im Turbo taktet (und der Lüfter entsprechend hochläuft), obwohl die CPU nur bei z.B. 20-30% Auslastung läuft. Als Energieprofil habe ich natürlich "Beste Leistung" eingestellt.
Würde mich einfach interessieren, was da der technische Hintergrund ist. Danke schon mal.