



- Registriert
- 25 Sep. 2010
- Beiträge
- 527
Servus...
ich bin kein Linux Profi und brauche daher bitte Eure Hilfe. Ich versuche mal alles am besten zu umschreiben, damit Ihr Euch ein Bild machen könnt. Ich habe einen kleinen Rechner gekauft - meines Wissens ist es so ein ARM Rechner - ähnlich dem Raspery - nur jedoch mit größerer Platine (microATX), echten RAM Riegeln, passiv gekühlt. Als Speicher dient eine PCIe NVMe 2 TB SSD. Diesen Rechner betreibe ich als Server - installiert habe ich ein Linux Ubuntu (aktuellste Version).
Erstes Problem.
Dieser kleine Server dient für eine Gruppe von kreativen Künstlern als Workspace hier bei mir. Es sind verschiedene Benutzer eingerichtet, verschiedene Rechte des Zugriffes auf Ordner und freigegebene Netzlaufwerke - was alles einwandfrei funktioniert hat - bis heute Morgen. Seitdem kann ich den "Server" Rechner nicht mehr hoch fahren.
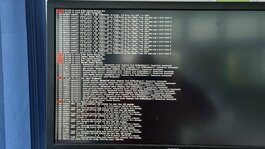
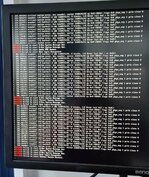
Ich habe Euch mal zwei Bilder angehängt - diese Meldung kam heute Vormittag.
1. Dann habe ich mal gewartet bis heute Nachmittag. Wenn ich den Rechner nun anschalte, dann kommt gar nichts mehr - als nur das Bild des Start-BIOS und dann nur noch ein blinkender Cursor. Sonst gar nichts.
2. Dann habe ich mal testweise die SSD ausgebaut - dann startet wenigstens der Rechner, bringt aber, dass er kein Betriebssystem hat, das er booten kann. Aber immerhin kommt eine Fehlermeldung bei ausgebauter SSD, anstatt wie bei (1) nur der blinkende Cursor.
3. Da ich für mich paar Daten brauche, dachte ich, probiere doch mal aus die SSD in ein T490s zu brauen und zu booten. Dachte das klappt mit Linux so einfach die SSD in einen anderen Rechner und starten. Tut es aber nicht - es kommen Meldungen wie fehlendes ACPI (oder so ähnlich) und ich soll ein manuelles fsck laufen lassen. Aber da traue ich mich erst mal nicht weiter - daher habe ich da jetzt mal nicht weiter gemacht.
* Ok - das ist der Stand des Rechners / Servers mit der SSD. Könnt Ihr bereits da was erkennen was schief gelaufen ist oder läuft?
* Da ich an die Daten heran kommen sollte - überlege ich mir einen PCIe NVMe USB Adapter zu kaufen um die SSD auszulesen. Kann ich die SSD einfach an einen Windows oder Mac Rechner anschließen und die Daten auslesen?
So und jetzt kommt das zweite Problem!
Daten von der SSD auslesen? Hast Du etwa kein Backup Deiner Daten? Doch!
Ich habe an den Linus Rechner / Server eine externe USB HDD angeschlossen. Ubuntu Linux bietet ein eigenes Backup Programm an, dass selbständig die Daten vom Rechner auf ein anderes Medien sichert. Das habe ich auch gemacht! Aber - ich weiß nicht 100% auch seit heute - die externe HDD ist auf einmal leer! Das ist ganz komisch.
Auf der externen HDD gibt es einen Order "linuxserver" (das ist der Rechnername) mit einem TimeStamp vom Dezember 2022. An dem Tag habe ich das erste Mal das Linux Backup Tool gestartet und dabei hat es diesen Ordner erzeugt. Und in diesen Ordner hinein macht das hauseigene Ubuntu Backup Tool ja die Backups. Und ich habe auch immer wieder mal die externe HDD kontrolliert! Und die Ordner waren da! Ich kann nicht sagen ob wirklich immer alles gesichert wurde bis zur letzten Datei - aber unter "linuxserver" waren einzelne Backup Ordner mit meinen ganzen Ordnern und Dateien! Und jetzt - ist nur noch der leere Ordner da!
Also das ein backup nur teilweise gemacht wurde oder einzelne Dateien nicht vorhanden mag alles vorkommen - aber der Linux Server, respektive das Ubuntu backup Programm, löscht doch nicht in dem Haupt-Backup-Ordner auf einmal alle Inhalte!?!
* Entweder Ihr sagt mir jetzt - dass ich mit einem Windows bzw. Mac Rechner auch gar nicht die Ordner und Dateien sehe wenn ich auf die externe HDD anschließe. Das ich dafür Linux benötige.
* Oder ich weiß auch nicht. Man könnte fast meinen - jemand hat auf die externe USB HDD zugegriffen und unter dem Backupordner alle Dateien per Hand gelöscht!? Also ich habe noch nie erlebt, dass ein Backup Programm Ordner und Dateien gelöscht hat - aber den "Ober-Ordner" übrig gelassen hat. Da müsste doch die ganze externe HDD verkorkst sein?
Ok. Ich bitte um Hilfe. Hat jemand Tipps wie ich bei dem Linux Rechner / Server am besten vorgehe? Kann jemand den Log lesen? Kann ich die SSD in ein Thinkpad einbauen zum Testen? Soll ich die interne Linux SSD an einen USB NVMe Adapter anschließen und versuchen mit meinen anderen Rechnern darauf zuzugreifen?
Was ist mit der externen Backup HDD passiert? Kann sich jemand vorstellen was da passiert sein könnte? Dass die SSD heute ausfällt und gleichzeitig auf der externen HDD auf einmal der Oberordner noch da ist aber die Unterordner alle gelöscht - finde ich einen ziemlich komischen Zufall.
DANKE!
ich bin kein Linux Profi und brauche daher bitte Eure Hilfe. Ich versuche mal alles am besten zu umschreiben, damit Ihr Euch ein Bild machen könnt. Ich habe einen kleinen Rechner gekauft - meines Wissens ist es so ein ARM Rechner - ähnlich dem Raspery - nur jedoch mit größerer Platine (microATX), echten RAM Riegeln, passiv gekühlt. Als Speicher dient eine PCIe NVMe 2 TB SSD. Diesen Rechner betreibe ich als Server - installiert habe ich ein Linux Ubuntu (aktuellste Version).
Erstes Problem.
Dieser kleine Server dient für eine Gruppe von kreativen Künstlern als Workspace hier bei mir. Es sind verschiedene Benutzer eingerichtet, verschiedene Rechte des Zugriffes auf Ordner und freigegebene Netzlaufwerke - was alles einwandfrei funktioniert hat - bis heute Morgen. Seitdem kann ich den "Server" Rechner nicht mehr hoch fahren.
Ich habe Euch mal zwei Bilder angehängt - diese Meldung kam heute Vormittag.
1. Dann habe ich mal gewartet bis heute Nachmittag. Wenn ich den Rechner nun anschalte, dann kommt gar nichts mehr - als nur das Bild des Start-BIOS und dann nur noch ein blinkender Cursor. Sonst gar nichts.
2. Dann habe ich mal testweise die SSD ausgebaut - dann startet wenigstens der Rechner, bringt aber, dass er kein Betriebssystem hat, das er booten kann. Aber immerhin kommt eine Fehlermeldung bei ausgebauter SSD, anstatt wie bei (1) nur der blinkende Cursor.
3. Da ich für mich paar Daten brauche, dachte ich, probiere doch mal aus die SSD in ein T490s zu brauen und zu booten. Dachte das klappt mit Linux so einfach die SSD in einen anderen Rechner und starten. Tut es aber nicht - es kommen Meldungen wie fehlendes ACPI (oder so ähnlich) und ich soll ein manuelles fsck laufen lassen. Aber da traue ich mich erst mal nicht weiter - daher habe ich da jetzt mal nicht weiter gemacht.
* Ok - das ist der Stand des Rechners / Servers mit der SSD. Könnt Ihr bereits da was erkennen was schief gelaufen ist oder läuft?
* Da ich an die Daten heran kommen sollte - überlege ich mir einen PCIe NVMe USB Adapter zu kaufen um die SSD auszulesen. Kann ich die SSD einfach an einen Windows oder Mac Rechner anschließen und die Daten auslesen?
So und jetzt kommt das zweite Problem!
Daten von der SSD auslesen? Hast Du etwa kein Backup Deiner Daten? Doch!
Ich habe an den Linus Rechner / Server eine externe USB HDD angeschlossen. Ubuntu Linux bietet ein eigenes Backup Programm an, dass selbständig die Daten vom Rechner auf ein anderes Medien sichert. Das habe ich auch gemacht! Aber - ich weiß nicht 100% auch seit heute - die externe HDD ist auf einmal leer! Das ist ganz komisch.
Auf der externen HDD gibt es einen Order "linuxserver" (das ist der Rechnername) mit einem TimeStamp vom Dezember 2022. An dem Tag habe ich das erste Mal das Linux Backup Tool gestartet und dabei hat es diesen Ordner erzeugt. Und in diesen Ordner hinein macht das hauseigene Ubuntu Backup Tool ja die Backups. Und ich habe auch immer wieder mal die externe HDD kontrolliert! Und die Ordner waren da! Ich kann nicht sagen ob wirklich immer alles gesichert wurde bis zur letzten Datei - aber unter "linuxserver" waren einzelne Backup Ordner mit meinen ganzen Ordnern und Dateien! Und jetzt - ist nur noch der leere Ordner da!
Also das ein backup nur teilweise gemacht wurde oder einzelne Dateien nicht vorhanden mag alles vorkommen - aber der Linux Server, respektive das Ubuntu backup Programm, löscht doch nicht in dem Haupt-Backup-Ordner auf einmal alle Inhalte!?!
* Entweder Ihr sagt mir jetzt - dass ich mit einem Windows bzw. Mac Rechner auch gar nicht die Ordner und Dateien sehe wenn ich auf die externe HDD anschließe. Das ich dafür Linux benötige.
* Oder ich weiß auch nicht. Man könnte fast meinen - jemand hat auf die externe USB HDD zugegriffen und unter dem Backupordner alle Dateien per Hand gelöscht!? Also ich habe noch nie erlebt, dass ein Backup Programm Ordner und Dateien gelöscht hat - aber den "Ober-Ordner" übrig gelassen hat. Da müsste doch die ganze externe HDD verkorkst sein?
Ok. Ich bitte um Hilfe. Hat jemand Tipps wie ich bei dem Linux Rechner / Server am besten vorgehe? Kann jemand den Log lesen? Kann ich die SSD in ein Thinkpad einbauen zum Testen? Soll ich die interne Linux SSD an einen USB NVMe Adapter anschließen und versuchen mit meinen anderen Rechnern darauf zuzugreifen?
Was ist mit der externen Backup HDD passiert? Kann sich jemand vorstellen was da passiert sein könnte? Dass die SSD heute ausfällt und gleichzeitig auf der externen HDD auf einmal der Oberordner noch da ist aber die Unterordner alle gelöscht - finde ich einen ziemlich komischen Zufall.
DANKE!
")
")






